
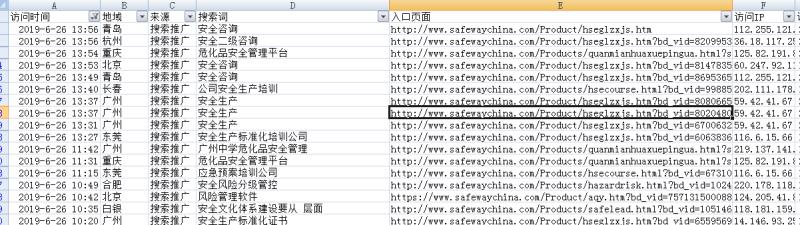
之前有研究过爬取一个网站中所有网页的URL脚步,后来再去用的时候发现是错误的,所以就想着再写一个。刚开始想来想去想不到办法,因为要抓取网站下所有页面的URL需要使用到递归,而python中递归使用次数是有限制的,超过了就会跑错。于是百度一下看看有没有解决的办,搜来搜去就发现了以下的这段代码:
import requestsfrom bs4 import BeautifulSoup as Bs4
head_url = "http://www.xxx.com.cn"headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}def get_first_url():
list_href = []
reaponse = requests.get(head_url, headers=headers)
soup = Bs4(reaponse.text, "lxml")
urls_li = soup.select("#mainmenu_top > div > div > ul > li")
for url_li in urls_li:
urls = url_li.select("a")
for url in urls:
url_href = url.get("href")
list_href.append(head_url+url_href)
out_url = list(set(list_href))
return out_url
def get_next_url(urllist):
url_list = []
for url in urllist:
response = requests.get(url,headers=headers)
soup = Bs4(response.text,"lxml")
urls = soup.find_all("a")
if urls:
for url2 in urls:
url2_1 = url2.get("href")
if url2_1:
if url2_1[0] == "/":
url2_1 = head_url + url2_1
url_list.append(url2_1)
if url2_1[0:24] == "http://www.xxx.com.cn":
url2_1 = url2_1
url_list.append(url2_1)
else:
pass else:
pass else:
pass else:
pass
url_list2 = set(url_list)
for url_ in url_list2:
res = requests.get(url_)
if res.status_code ==200:
print(url_)
print(len(url_list2))
get_next_url(url_list2)if __name__ == "__main__":
urllist = get_first_url()
get_next_url(urllist)有基础的人一看也会发现,这其实也是一种深度递归,遇到网页数量稍微多一点的就会超量跑错。于是我尝试了新的方法,使用线程就完美解决了。并且直接升级成了检查网站中是否存在404页面的工具。想要代码的可以来公众号看






评论